Machine Learning - UnSupervised Learning - K Mean Clustering Tutorial
K-Means clustering is most commonly used unsupervised learning algorithm to find groups in unlabeled data. Here K represents the number of groups or clusters and the process of creating these groups is known as clustering.
In this, the process is repeated until convergence or till it does not find the best clusters.

Step to achieve clustering-
step 1] - Finalize the number of cluster you want to identify in your data. This is the K in K mean clustering.
step 2] - Now randomly initialize the points or centroid anywhere in dataset equal to the number of clusters K.
step 3] - Assign cluster based on the centroid and point near to the centroid.
step 4] - Then again find the centroid using mean/average of cluster that has formed in step 3, the centroid is slightly moved from earlier centroid position
If the centroid moved from earlier centroid position, then again repeat step 3 and step 4 till it get converge(Or the centroid stopped moving).
step 5] - Once the centroid stopped moving. Then the final cluster and cluster centroid will formed

How to choose number of cluster?
To choose number of cluster, we can use-
1] Visualization-
If we have domain knowledge and proper understanding of given data which also help to make more informed decisions.
Some clusters are visible by naked eye.
2] Elbow method
Elbow method is widely used method to find number of cluster in dataset. The elbow method constitutes running K-Means clustering on the dataset.
Elbow method is achieved by plotting graph between no. of cluster on x axis and WSS (Within sum of squared distance) or inertia on y axis.
In this, we run the K-Means algorithm multiple times over a loop, with an increasing number of cluster choice(say from 1 to 10) and then plotting a graph with respect to WSS and no. of cluster.
For one cluster or one centroid, WSS is calculated by totaling the squared euclidian distance between the each point and centroid.
Example for 1 centroid and 50 data point, the WSS = d12 + d22 + d32 + …. d502
And for 50 centroid and 50 data point, the WSS = 0, because distance become zero for all centroid, as all centroid are itself a datapoint.
Which means as the cluster increase then WSS decrease.
After certain point the graph become steady in the form of elbow, that steady point/elbow point can be determined as the number of cluster. In the below graph we can determine the number of cluster as 3
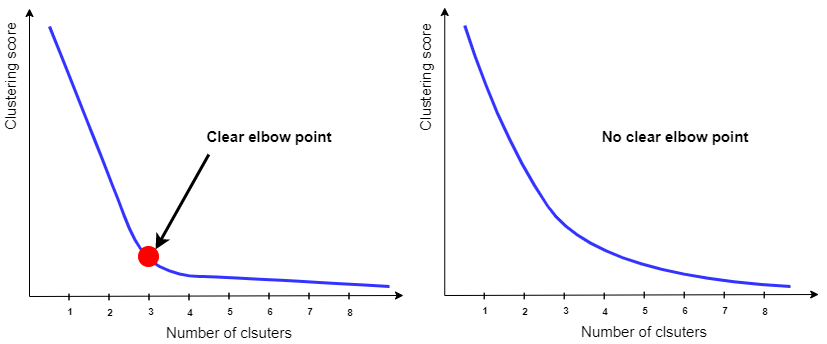
But sometimes we don’t get clear elbow point on the plot, in such cases its very hard to finalize the number of clusters.
See video number 103
Advantages-
- One of the simplest algorithm to understand and efficient
- It can work on any dimension with same piece of code.
- Gives better results when there is less data overlapping
Disadvantages-
- Number of clusters need to be defined by user
- Doesn’t work well in case of overlapping data
- Unable to handle the noisy data and outliers
- Algorithm fails for non-linear data set
Compare K-means and KNN Algorithms.
|
K-means |
KNN |
|
|
- Hierarchical Clustering
- PCA