Machine Learning - Supervised Learning - Naïve Bayes Classifier [classification] Tutorial
Naïve Bayes algorithm is a supervised learning algorithm, which is based on Bayes theorem and used for solving classification problems.
It is mainly used in text classification that includes a high-dimensional training dataset. For example- spam filtration, Sentimental analysis, and classifying articles.
It is a probabilistic classifier, which means it predicts on the basis of the probability of an object.
Why it is called naive bayes?
The classifier is called ‘naive’ because it makes assumptions that may or may not be correct.
The algorithm assumes that the presence of one feature of a class is not related to the presence of any other feature.
For instance, a fruit may be considered to be a cherry if it is red in color and round in shape, regardless of other features. This assumption may or may not be right (as an apple also matches the description).
It is called Bayes because it depends on the principle of Bayes' Theorem
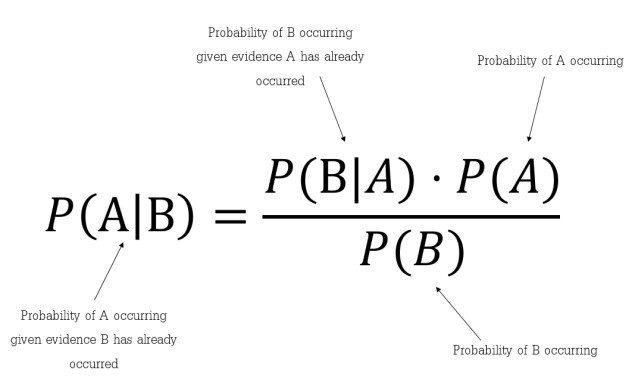
Bayes Theorem-
It is used to determine the probability of a hypothesis with prior knowledge. It depends on the conditional probability.
Where,
P(A|B) is Posterior probability: Probability of hypothesis A on the Observed event B.
P(B|A) is Likelihood probability: Probability of the evidence given that the probability of a hypothesis is true.Or(probability of B, if A already occurred)
P(A) is Prior Probability: Probability of hypothesis before observing the evidence.
P(B) is Marginal Probability: Probability of Evidence
Advantage Of Naive Bayes Classifier-
It is one of the fast and easy ML algorithms to predict a class of datasets.
It is used for binary as well as multi class classifications.
It is most popular choice for text classification problems.
Disadvantage Of Naive Bayes Classifier-
Naive Bayes assumes that all features are independent or unrelated, so it cannot learn the relationship between features.
Types of Naïve Bayes Model:
There are three types of Naive Bayes Model, which are given below:
Gaussian: The Gaussian model assumes that each class is normal distributed. This means if predictors take continuous values instead of discrete, then the model assumes that these values are sampled from the Gaussian distribution.(e.g input variable is continuous)
Multinomial: The Multinomial Naïve Bayes classifier is used when the data is multinomial distributed. It is primarily used for document classification problems, it means a particular document belongs to which category such as Sports, Politics, education, etc.(e.g input variable is discrete i.e Sunny, Rainy, cloudy etc)
The classifier uses the frequency of words for the predictors.
Bernoulli: The Bernoulli classifier works similar to the Multinomial classifier, but the predictor variables are the independent Booleans variables. Such as if a particular word is present or not in a document. This model is also famous for document classification tasks. (e.g input variable is boolean i.e 1 or 0 ,True or False)